Vous vous êtes déjà arrêté net face à un code 404 ou un 500 Internal Server Error en gérant votre site web ?
Ces mystérieux codes de statut HTTP régissent pourtant chaque interaction en ligne.
Décryptez ici la liste complète des codes de statut HTTP pour maîtriser leur impact sur votre SEO, vos APIs ou vos outils de monitoring, avec des explications claires pour optimiser votre veille tech et éviter les blocages inutiles.
Sommaire
Comprendre les codes de statut HTTP
Les codes de statut HTTP sont des réponses numériques à 3 chiffres envoyées par un serveur pour indiquer le résultat d’une requête. Ils se divisent en 5 classes : 1xx (informations), 2xx (succès), 3xx (redirection), 4xx (erreurs client) et 5xx (erreurs serveur).
Des codes comme 200 OK ou 404 Not Found aident à diagnostiquer des problèmes, gérer le cache et optimiser la navigation. Normalisés par des RFC et l’IANA, ces codes structurent la communication client-serveur sur le web.
Les codes HTTP sont des réponses à trois chiffres indiquant le résultat d’une requête serveur.
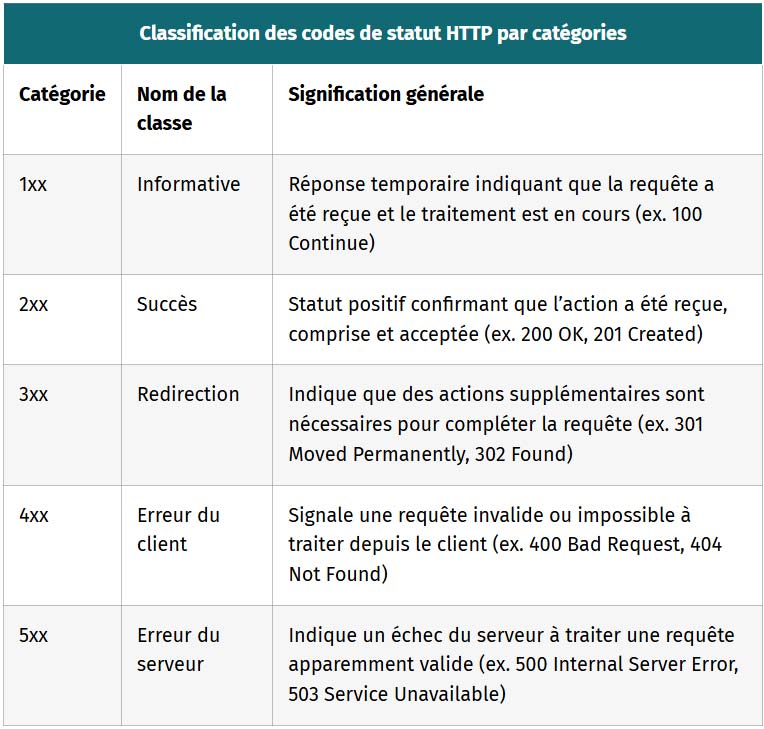
| Classification des codes de statut HTTP par catégories | ||
|---|---|---|
| Catégorie | Nom de la classe | Signification générale |
| 1xx | Informative | Réponse temporaire indiquant que la requête a été reçue et le traitement est en cours (ex. 100 Continue) |
| 2xx | Succès | Statut positif confirmant que l’action a été reçue, comprise et acceptée (ex. 200 OK, 201 Created) |
| 3xx | Redirection | Indique que des actions supplémentaires sont nécessaires pour compléter la requête (ex. 301 Moved Permanently, 302 Found) |
| 4xx | Erreur du client | Signale une requête invalide ou impossible à traiter depuis le client (ex. 400 Bad Request, 404 Not Found) |
| 5xx | Erreur du serveur | Indique un échec du serveur à traiter une requête apparemment valide (ex. 500 Internal Server Error, 503 Service Unavailable) |

Les codes d'information (1xx)
Les codes 1xx sont des réponses informatives provisoires indiquant que le serveur a reçu la requête et la traite. Ils permettent de garder la communication active sans bloquer le client.
Moins connus que les 404 ou 500, ces codes optimisent les échanges en évitant les envois inutiles de données lourdes. Bien qu’opaques pour l’utilisateur final, ils améliorent l’efficacité des requêtes complexes ou longues.
100 Continue
Le code 100 Continue indique que le serveur a reçu la première partie d’une requête complexe et est prêt à recevoir la suite. Le client doit poursuivre l’échange après avoir obtenu cette réponse.
L’en-tête « Expect: 100-continue » déclenche souvent cette réponse, évitant l’envoi inutile de données lourdes si le serveur les rejette par la suite. Ce mécanisme optimise la bande passante et améliore l’efficacité des requêtes HTTP.
101 Switching Protocols
Le code 101 Switching Protocols permet au serveur d’accepter un changement de protocole demandé par le client via l’en-tête Upgrade. Utilisé pour passer à WebSocket ou une version d’HTTP plus récente, il déclenche une réponse avec les en-têtes Upgrade et Connection: Upgrade pour établir la nouvelle connexion.
102 Processing
Le code 102 Processing, introduit dans WebDAV via le RFC 2518, indique qu’une requête est en cours de traitement long. Il maintient la connexion active pour éviter les timeouts. Retiré dans le RFC 4918, il reste utile pour les opérations complexes nécessitant du temps serveur.
103 Early Hints
Le code 103 Early Hints optimise le chargement des ressources en envoyant des indications avant la réponse finale. Le serveur utilise l’en-tête Link pour précharger CSS ou JS. Cette anticipation réduit la latence et accélère le rendu de la page.

Les codes de succès (2xx)
Les codes 2xx signalent le succès d’une requête HTTP. Ils rassurent les moteurs de recherche sur l’accessibilité du contenu. Le code 200 OK est le plus courant, indiquant que la requête a réussi. Ces réponses positives structurent les échanges client-serveur sur le web.
- 200 OK : Accéder à une page web via une requête GET
- 201 Created : Créer un nouveau compte utilisateur via une requête POST
- 202 Accepted : Traiter une demande complexe en arrière-plan sans bloquer le client
- 204 No Content : Confirmer une action sans nécessiter de nouvelle page ou données
- 206 Partial Content : Diffuser une vidéo ou un gros fichier en segments via l’en-tête Range
200 OK
Le code 200 OK signale que la requête HTTP a été traitée avec succès par le serveur. Il est renvoyé lorsqu’un navigateur accède à une page existante via une méthode GET ou après une action réussie en POST/PUT.
Ce statut est crucial pour le référencement, car il garantit que le contenu est accessible aux moteurs de recherche et aux utilisateurs.
201 Created
Le code 201 Created indique qu’une requête a abouti à la création d’une ressource. Il est associé aux méthodes POST ou PUT quand une nouvelle URL est générée. La réponse inclut un en-tête Location avec l’URI de la ressource et peut contenir des métadonnées décrivant sa structure.
202 Accepted
Le code 202 Accepted indique qu’une requête a été acceptée sans être traitée immédiatement. Utilisé pour les opérations asynchrones, il inclut souvent une URL de suivi via l’en-tête Location. Exemple : traitement d’images en arrière-plan après réception de la demande initiale.
203 Non-Authoritative Information

Le code 203 signale qu’un intermédiaire a modifié la réponse originale du serveur. Un proxy peut transformer le contenu pour optimiser la compatibilité, sécuriser les données ou adapter le format. L’utilisation de l’en-tête Warning 214 Transformation Applied reste préférable pour conserver le statut d’origine.
204 No Content
Le code 204 No Content confirme le succès d’une requête sans renvoyer de contenu. Utilisé pour des actions comme la suppression en API ou les sauvegardes en arrière-plan, il évite le rechargement de la page. Cacheable par défaut, il inclut souvent un en-tête ETag pour valider l’état de la ressource.
205 Reset Content
Le code 205 Reset Content demande au client de réinitialiser la vue d’un document après une requête réussie. Utilisé principalement pour les formulaires, il efface les champs après soumission.
Contrairement au 204 No Content, ce statut impose une action sur l’interface. Peu courant, il optimise les expériences nécessitant une réinitialisation automatique post-édition.
206 Partial Content
Le code 206 Partial Content permet de répondre à des requêtes de plages spécifiques via l’en-tête Range. Utilisé pour le streaming vidéo/audio ou les reprises de téléchargement, il inclut l’en-tête Content-Range pour indiquer la portion transmise. Optimise les performances en évitant de transférer des fichiers entiers.
207 Multi-Status
Le code 207 Multi-Status, spécifique à WebDAV, structure les réponses multiples via XML. Utilisé lors d’opérations combinées, chaque réponse est encapsulée dans un élément response avec son statut propre. Le format exclut les codes 1xx pour éviter les doublons, conformément au RFC 4918.
208 Already Reported
Le code 208 Already Reported évite les doublons dans les réponses 207 Multi-Status WebDAV. Utilisé quand une ressource comme « Loop Demo » est référencée plusieurs fois, il économise de l’espace. Non standard, il est supporté par Chrome et Nginx.
226 IM Used
Le code 226 IM Used indique que le serveur a appliqué des manipulations d’instance à une ressource, comme la compression delta ou la réduction de données. Défini par le RFC 3229, il optimise la bande passante en envoyant uniquement les différences entre les versions, utile pour les clients possédant une version en cache.

Les codes de redirection (3xx)
Les codes 3xx exigent une action complémentaire pour aboutir à une requête. Le 301 définitif transfère le référencement d’une URL, le 302 temporaire l’ignore. Le 304 valide le cache, optimisant les performances sans recharger le contenu. Ces statuts structurent la navigation et influencent le SEO.
300 Multiple Choices
Le code 300 Multiple Choices signale qu’une ressource a plusieurs versions disponibles. Le serveur liste les options via des en-têtes comme Link ou dans un corps de réponse HTML/JSON. L’utilisateur ou le client doit choisir une version. Peu utilisé, il nécessite une interface claire pour éviter la confusion.
- Quand utiliser le code 300 ? Pour proposer des variantes d’une ressource (ex. versions multilingues).
- Quels formats peuvent être concernés ? HTML, JSON, ou métadonnées décrivant chaque option.
- Comment le client choisit-il ? Via un lien cliquable ou en spécifiant un paramètre dans la requête suivante.
301 Moved Permanently
Le code 301 redirige définitivement une URL vers une nouvelle, transférant le « link equity » aux moteurs de recherche. Utilisé pour migrer de domaine, modifier une URL ou remplacer une page supprimée, il évite la perte de trafic.
Depuis 2016, Google ne pénalise plus le PageRank via les 301, contrairement à l’époque où 15% de l’autorité était perdue.
- Suppression de page : rediriger vers une ressource équivalente pour conserver le trafic
- Changement de domaine : migrer l’intégralité du site avec des règles serveur
- Optimisation d’URL : rediriger les anciens slugs vers les nouveaux formats
- Consolidation de contenu : unifier les signaux SEO de pages similaires
- Gestion des variations : forcer www ou HTTPS pour éviter les doublons
302 Found (Moved Temporairement)
Le code 302 redirige temporairement vers une nouvelle URL, utile pour les tests A/B ou les mises à jour éphémères. Les moteurs de recherche ne transfèrent pas le « link equity » et les navigateurs suivent automatiquement la redirection.
Lorsqu’une maintenance est en cours, ce code prévient les utilisateurs sans nuire au référencement de l’URL originale.
- Quand privilégier une redirection 302 ? Pour des tests A/B, pages de maintenance, ou contenu saisonnier.
- Quel est son impact SEO ? Google ne transfère pas le « link equity », conservant l’URL d’origine dans son index.
- Comment les navigateurs la gèrent-ils ? Le code 302 déclenche un redirigement automatique vers l’URL spécifiée dans l’en-tête Location.
303 See Other
Le code 303 See Other redirige vers une URL différente via l’en-tête Location, en imposant une méthode GET pour la requête suivante.
Contrairement au 302 Found, il force le client à utiliser GET après un POST, évitant les envois multiples de formulaires. Utile pour les confirmations post-soumission.
- Quelle est la différence entre 302 et 303 ? Le code 303 impose une requête GET pour l’URI de destination, tandis que le 302 autorise toutes méthodes.
- Comment s’intègre-t-il dans le flux de formulaires web ? Après soumission POST, le serveur répond avec 303 et l’URI de confirmation dans l’en-tête Location.
- Pourquoi utiliser GET après POST ? Pour éviter la répétition des données envoyées et garantir une navigation sans risque lors des rafraîchissements.
304 Not Modified
Le code 304 Not Modified active le cache en évitant de retransmettre des ressources inchangées. Le serveur compare les en-têtes ETag ou If-Modified-Since envoyés par le client avec l’état actuel de la ressource.
Si aucune modification n’est détectée, il répond avec 304, économisant bande passante et accélérant le chargement.

307 Temporary Redirect
Le code 307 force la conservation de la méthode et du corps de la requête initiale lors d’une redirection temporaire. Contrairement au 302 Found, il prévient les risques liés au changement de méthode HTTP.
Utilisé pour des tests ou des mises à jour éphémères, il évite de perdre les données POST lors de la redirection.
- À quelle occasion utiliser le 307 ? Pour des tests A/B nécessitant la préservation de la méthode d’origine (ex. formulaires).
- Quelle est la différence avec le 302 ? Le 302 peut passer de POST à GET, le 307 maintient la méthode initiale.
- Pourquoi préférer 301 aux 307 pour les changements durables ? Le 301 transfère le « link equity » et est indexé par Google, contrairement au 307.
308 Permanent Redirect
Le code 308 conserve la méthode HTTP d’origine lors de redirections permanentes, contrairement au 301 qui peut passer de POST à GET. Idéal pour les formulaires et API, il évite la perte de données. Google le traite comme un 301 pour le référencement.
- Quand utiliser le 308 ? Pour des déplacements permanents nécessitant la préservation de la méthode d’origine (ex. endpoints API).
- Comment gère-t-il les données de formulaire ? Maintient les requêtes POST durant la redirection, évitant la perte de contenu.
- Quel impact SEO ? Google le considère comme un 301, transférant l’autorité sans nuire au référencement.
Les codes d'erreur du client (4xx)
Les codes 4xx signalent des erreurs du côté client, comme des requêtes malformées ou des accès refusés. Le code 404 Not Found est le plus courant, indiquant une ressource introuvable.
Ces erreurs impactent l’expérience utilisateur et le SEO si elles persistent. Leur diagnostic nécessite l’analyse des logs serveur et des requêtes envoyées.
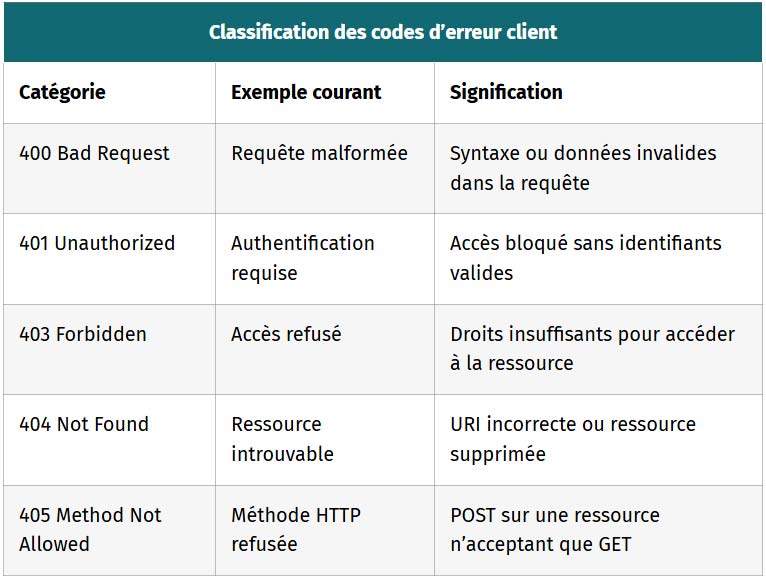
| Classification des codes d’erreur client | ||
|---|---|---|
| Catégorie | Exemple courant | Signification |
| 400 Bad Request | Requête malformée | Syntaxe ou données invalides dans la requête |
| 401 Unauthorized | Authentification requise | Accès bloqué sans identifiants valides |
| 403 Forbidden | Accès refusé | Droits insuffisants pour accéder à la ressource |
| 404 Not Found | Ressource introuvable | URI incorrecte ou ressource supprimée |
| 405 Method Not Allowed | Méthode HTTP refusée | POST sur une ressource n’acceptant que GET |
400 Bad Request
Le 400 Bad Request signale une requête HTTP malformée ou des données invalides envoyées par le client. Fréquent en développement API ou formulaires, il survient quand la syntaxe est incorrecte, un en-tête manquant ou un corps de requête illisible. Une réponse claire avec des détails d’erreur facilite le débogage.
- Quand un 400 est-il renvoyé ? Lorsque la syntaxe de la requête est invalide (ex. JSON mal formé), ou des données inadaptées (ex. type numérique attendu mais chaîne reçue).
- Quels exemples concrets ? Un formulaire envoyé avec un email mal formaté, ou une requête API avec un paramètre de type inattendu.
- Comment le diagnostiquer ? Vérifier les logs serveur, tester avec Postman ou curl, et valider les données avant l’envoi.
401 Unauthorized
Le code 401 Unauthorized indique que la requête manque d’informations d’authentification valides. Contrairement au 403 Forbidden, il signifie un problème d’identification, pas de droits insuffisants. Pour le résoudre, le client doit inclure des identifiants (ex. token Bearer) dans l’en-tête Authorization.

402 Payment Required
Le code 402 Payment Required est réservé pour des usages futurs liés aux paiements, sans implémentation actuelle. Il pourrait indiquer un blocage nécessitant un règlement, mais reste inutilisé dans les serveurs modernes. Sa spécification dans le RFC 7235 prévoit un usage pour des transactions, sans adoption concrète.
403 Forbidden
Le code 403 Forbidden bloque l’accès à une ressource serveur malgré une syntaxe HTTP valide. Contrairement au 401 Unauthorized, il signifie un refus définitif lié aux permissions, non à l’authentification.
Impossible à résoudre côté utilisateur, il nécessite une intervention technique sur les droits d’accès ou la configuration serveur. Ces erreurs de permissions font partie des aspects cruciaux pour sécuriser votre site internet.
- Ressource non indexée : Serveur configuré pour interdire la liste des fichiers d’un répertoire
- Droits insuffisants : Fichiers avec permissions restrictives (ex. 600 au lieu de 644)
- IP bloquée : Blocage par .htaccess ou pare-feu serveur
- Fichier .htpasswd manquant : Authentification Apache configurée sans fichier valide
- Erreurs de configuration : Directive Files ou Directory mal paramétrée dans le Vhost
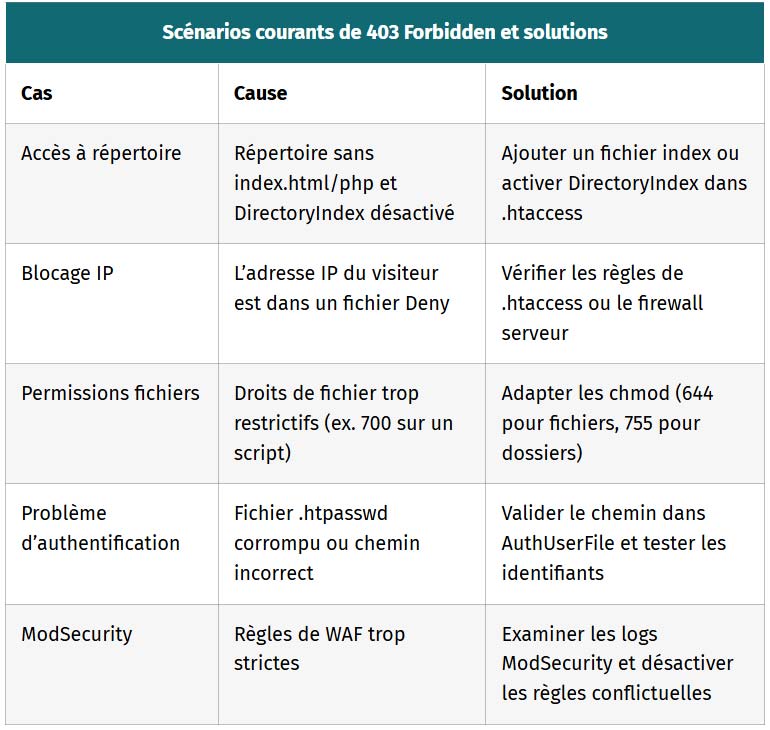
| Scénarios courants de 403 Forbidden et solutions | ||
|---|---|---|
| Cas | Cause | Solution |
| Accès à répertoire | Répertoire sans index.html/php et DirectoryIndex désactivé | Ajouter un fichier index ou activer DirectoryIndex dans .htaccess |
| Blocage IP | L’adresse IP du visiteur est dans un fichier Deny | Vérifier les règles de .htaccess ou le firewall serveur |
| Permissions fichiers | Droits de fichier trop restrictifs (ex. 700 sur un script) | Adapter les chmod (644 pour fichiers, 755 pour dossiers) |
| Problème d’authentification | Fichier .htpasswd corrompu ou chemin incorrect | Valider le chemin dans AuthUserFile et tester les identifiants |
| ModSecurity | Règles de WAF trop strictes | Examiner les logs ModSecurity et désactiver les règles conflictuelles |
404 Not Found
Le code 404 signale une ressource introuvable sur le serveur. Cela survient quand une URL est incorrecte, la page supprimée ou les règles de routage mal configurées. Google pénalise moins cette erreur depuis 2020, mais une accumulation de liens brisés nuit à l’expérience utilisateur et au référencement.
- Changement d’URL : Une page déplacée sans redirection 301 génère des 404
- Faute de frappe : Une erreur dans l’adresse tapée manuellement par l’utilisateur
- Lien mort externe : Un site tiers pointe vers une ressource supprimée
- Réécriture d’URL : Une règle de .htaccess mal calibrée bloque l’accès
- Fichier supprimé : Un administrateur retire un document sans vérifier les liens entrants
- Page personnalisée : Créer une 404 claire avec moteur de recherche interne et liens utiles
- Monitoring régulier : Utiliser Screaming Frog ou Google Search Console pour détecter les erreurs
- Redirections 301 : Récupérer le trafic perdu en réorientant vers des pages actives
- Analytics détaillés : Suivre les sources des erreurs pour corriger les sources récurrentes
- Prévention proactive : Vérifier les liens sortants avant publication
Le code 404 indique qu’aucune ressource correspondante n’a été trouvée sur le serveur.
405 Method Not Allowed
Le code 405 Method Not Allowed survient quand une méthode HTTP non supportée est utilisée. Le serveur renvoie l’en-tête Allow pour lister les méthodes autorisées. Utile pour les APIs, il empêche les requêtes inadaptées sur des ressources en lecture seule.
406 Not Acceptable
Le code 406 Not Acceptable survient quand aucune version de la ressource ne correspond aux critères de négociation envoyés via les en-têtes Accept, Accept-Charset ou If-Match. Le serveur ne peut pas satisfaire les préférences du client, obligeant à ajuster les paramètres ou à accepter une réponse par défaut.
- Pourquoi un 406 est-il renvoyé ? Quand les en-têtes du client (ex. Accept-Language) ne correspondent à aucune version disponible de la ressource.
- Comment fonctionne la négociation de contenu ? Le serveur compare les préférences du client avec ses formats supportés pour choisir la meilleure version.
- Quelle solution pour l’utilisateur ? Modifier les paramètres de requête ou utiliser un client plus flexible sur les formats acceptables.
407 Proxy Authentication Required
Le code 407 Proxy Authentication Required oblige le client à s’authentifier auprès d’un serveur intermédiaire. Le navigateur doit inclure un en-tête Proxy-Authorization avec des identifiants valides. Contrairement au 401 Unauthorized, cette erreur concerne spécifiquement l’authentification via un proxy.
- Pourquoi le code 407 est-il renvoyé ? Quand un proxy exige une authentification avant de transmettre la requête au serveur final, sans que les identifiants soient fournis.
- Comment fonctionne l’authentification proxy ? Le client reçoit un 407 avec l’en-tête Proxy-Authenticate, puis répète la requête avec Proxy-Authorization.
- Quels en-têtes sont nécessaires ? Proxy-Authenticate (définit les méthodes supportées) et Proxy-Authorization (contient les identifiants fournis par l’utilisateur).
408 Request Timeout
Le code 408 Request Timeout survient quand le client ne transmet pas la requête dans le délai imparti par le serveur. Il force le client à renvoyer les données ou abandonner. Ce mécanisme évite les attentes infinies et libère les ressources serveur inutilisées.
- Quand le 408 est-il renvoyé ? Lorsque le délai de réception du corps de la requête est dépassé (ex. upload interrompu).
- Comment le client doit-il réagir ? Retenter l’envoi ou ajuster les en-têtes comme Expect: 100-continue pour éviter les timeouts.
- Quels problèmes résout-il ? Évite la consommation inutile de mémoire ou bande passante sur des requêtes incomplètes.
409 Conflict
Le code 409 Conflict survient quand une requête entre en conflit avec l’état actuel d’une ressource. Le client doit résoudre le conflit avant d’envoyer à nouveau la requête. Ce code est fréquent lors de modifications simultanées de fichiers ou de données versionnées en API.
- Quand le code 409 est-il renvoyé ? Quand une requête entre en conflit avec l’état actuel d’une ressource (ex. modification simultanée d’un fichier).
- Comment résoudre les conflits de version ? Via l’en-tête ETag ou Last-Modified pour vérifier la version avant d’écraser les données.
- Quels en-têtes facilitent la détection de conflits ? ETag et If-Match pour contrôler les mises à jour concurrentes.
410 Gone
Le code 410 indique qu’une ressource est intentionnellement supprimée et ne sera pas remplacée. Contrairement au 404, il informe les moteurs de recherche que cette page n’existe plus de manière définitive. Utile pour le SEO, il évite de conserver des URLs obsolètes dans l’index de Google.
- Quand utiliser le 410 ? Pour signaler la suppression permanente d’une page, comme un produit retiré ou un article désuet.
- Différence avec le 404 ? Le 404 suggère une disparition temporaire, le 410 confirme une suppression volontaire.
- Impact SEO ? Google retire plus rapidement les URLs en 410 de son index, contrairement aux 404 qui sont conservés plusieurs semaines.

411 Length Required
Le code 411 indique que le client n’a pas fourni d’en-tête Content-Length nécessaire pour une requête avec Expect: 100-continue. Le serveur refuse de continuer sans cette information, obligeant à corriger la requête pour éviter des envois incomplets.
- Quand le code 411 est-il renvoyé ? Lorsque l’en-tête Expect: 100-continue est présent sans Content-Length, empêchant l’envoi de données partielles.
- Comment le client doit-il réagir ? Ajouter l’en-tête Content-Length avec la taille exacte du corps de la requête avant de réémettre la demande.
- Quel problème résout-il ? Évite les requêtes incomplètes qui gaspillent des ressources serveur, forçant une validation préalable de la charge utile.
412 Precondition Failed
Le code 412 Precondition Failed survient quand une condition dans les en-têtes If-Match ou If-None-Match n’est pas remplie. Le client doit ajuster les paramètres ou renoncer. Ce statut garantit l’intégrité des mises à jour conditionnelles en évitant les écritures inadéquates.
- Pourquoi le code 412 est-il renvoyé ? Quand les en-têtes If-Match ou If-None-Match ne correspondent pas aux attentes du serveur.
- Comment le client doit-il réagir ? Modifier les conditions ou abandonner la requête pour éviter des actions non synchronisées.
- Quels en-têtes sont impliqués ? If-Match pour valider l’état d’une ressource, If-None-Match pour éviter les rechargements inutiles.
413 Payload Too Large
Le code 413 Payload Too Large survient quand la requête HTTP dépasse les limites de taille imposées par le serveur. Cela arrive souvent avec les formulaires volumineux ou les uploads de fichiers.
Pour résoudre ce problème, le client doit réduire la taille des données envoyées ou le serveur doit ajuster ses paramètres limites.
414 URI Too Long
Le code 414 survient quand l’URI envoyée dépasse les limites du serveur. Les requêtes GET avec trop de paramètres dans l’URL ou les formulaires mal configurés déclenchent cette erreur. Pour la résoudre, raccourcir l’URL, utiliser POST pour les données volumineuses ou ajuster la configuration serveur.
- Requêtes GET avec trop de paramètres : Les filtres complexes ou les identifiants longs dans l’URL dépassent les capacités du serveur
- Utilisation de navigateurs ou API limités : Certains clients ne gèrent pas les URLs dépassant 2048 caractères
- Configuration serveur stricte : Les paramètres Nginx (large_client_header_buffers) ou Apache (LimitRequestLine) bloquent les URI trop longues.
415 Unsupported Media Type
Le code 415 Unsupported Media Type survient quand le serveur ne supporte pas le format spécifié dans l’en-tête Content-Type de la requête. Le client doit ajuster le type MIME ou utiliser un format reconnu par le serveur pour que la requête soit traitée.
- Quand le code 415 est-il envoyé ? Quand la méthode POST ou PUT inclut un Content-Type non pris en charge par l’API ou le serveur web.
- Quels formats sont concernés par cette erreur ? JSON mal déclaré, XML refusé, ou types personnalisés non configurés sur le serveur.
- Comment résoudre le problème ? Vérifier le Content-Type envoyé, forcer le bon type (ex. application/json), ou configurer le serveur pour accepter le format utilisé.
416 Range Not Satisfiable
Le code 416 survient quand une requête spécifie une plage de données plus grande que la ressource. L’en-tête Range est invalide car le serveur ne peut pas satisfaire la demande. Le client doit ajuster les paramètres ou le serveur renvoyer le fichier complet.
- Quand le 416 est-il renvoyé ? Lorsqu’une requête spécifie une plage de données dépassant la taille de la ressource (ex. 0-500 sur un fichier de 300 octets).
- Comment éviter cette erreur ? Valider les plages demandées avant de les traiter, et limiter les requêtes partielles à la taille réelle de la ressource.
- Quelle solution côté serveur ? Renvoyer un 416 avec l’en-tête Content-Range indiquant la taille maximale acceptée, ou traiter la requête comme un 200 OK sans plage.
| Exemples concrets de 416 Range Not Satisfiable | ||
|---|---|---|
| Cas | Cause | Solution |
| Requête 0-1000 sur un fichier de 500 octets | Plage demandée plus grande que la ressource | Envoyer la ressource complète ou redémarrer la requête avec une plage valide |
| Paramètre Range mal formaté dans une vidéo | Erreur de syntaxe ou de calcul du client | Valider les en-têtes Range côté serveur avant traitement |
| Multiples requêtes partielles sur une ressource modifiée | La taille de la ressource a changé entre les requêtes | Utiliser ETag ou If-Match pour garantir la cohérence des versions |

417 Expectation Failed
Le code 417 Expectation Failed survient quand le serveur ne satisfait pas l’en-tête Expect envoyé par le client. La requête est rejetée sans traitement. Le client doit ajuster ses en-têtes ou abandonner l’envoi.
- Quand le code 417 est-il renvoyé ? Quand le serveur ne prend pas en charge l’attente spécifiée via l’en-tête Expect: 100-continue.
- Comment gérer l’en-tête Expect ? Supprimer l’en-tête Expect ou vérifier sa syntaxe avant de réémettre la requête.
- Quels en-têtes sont concernés ? Expect pour déclencher la vérification, et Connection: close si le serveur ne gère pas cette attente.
421 Misdirected Request
Le code 421 signale que le serveur ne peut traiter la requête à cause d’une mauvaise configuration. Cela arrive quand un client envoie une requête à un hôte incorrect, souvent avec HTTP/2 ou des hôtes virtuels. Le serveur indique qu’il ne peut pas router la requête, obligeant le client à réessayer avec des détails d’hôte précis.
422 Unprocessable Entity
Le code 422 survient quand le serveur comprend la requête mais ne peut la traiter à cause d’erreurs sémantiques. C’est le cas d’une API rejetant des données invalides (ex. formulaire mal rempli).
Le client doit corriger les erreurs avant de réémettre la requête. Ce statut, spécifique à WebDAV, précise que la syntaxe est correcte mais le contenu inacceptable.
- Quand utiliser le 422 ? Pour des requêtes syntaxiquement valides mais bloquées par des règles métier (ex. formulaire sans email valide).
- Quels sont les cas de validation échouée ? Valeurs de champs incorrectes, formats non conformes (ex. date au format JJ/MM/AAAA attendue en AAAA-MM-JJ), ou règles métier non respectées.
- Comment implémenter la validation ? Les serveurs renvoient des détails en JSON/XML pour guider l’utilisateur sur les champs à corriger, souvent avec des messages précis.
423 Locked
Le code 423 Locked, défini par WebDAV (RFC 4918), indique qu’une opération ne peut aboutir car une ressource est verrouillée. Le client doit inclure un en-tête If-Match avec l’ID de verrou valide pour contourner cette limitation. Ce statut structure les accès concurrents en environnement collaboratif.
- Quand le code 423 est-il utilisé ? Lors de tentatives d’édition simultanée sur un fichier verrouillé via WebDAV.
- Comment fonctionne le verrouillage WebDAV ? Via les en-têtes Lock-Token et If-Match pour gérer les accès concurrents.
- Quels outils facilitent la gestion des verrous ? Des outils comme Cadaver ou des APIs REST respectant les spécifications RFC 4918.
424 Failed Dependency
Le code 424 Failed Dependency survient quand une requête dépend d’une opération préalable ayant échoué. Utilisé avec WebDAV, il empêche les actions incomplètes en vérifiant l’état des ressources associées. Le client doit corriger les dépendances avant de réémettre la requête.
425 Too Early
Le code 425 Too Early survient quand une requête idempotente est envoyée trop rapidement après une précédente tentative. Le serveur refuse de la traiter pour éviter les doublons.
Utile en environnement concurrent, il force le client à attendre un délai avant de renvoyer sa requête, évitant ainsi des opérations répétitives inutiles.
426 Upgrade Required
Le code 426 Upgrade Required incite le client à passer à un protocole supérieur pour communiquer. Le serveur spécifie les protocoles acceptés via l’en-tête Upgrade. Cela évite les requêtes incompatibles, comme un client HTTP/1.1 tentant d’accéder à une API nécessitant HTTP/2, ou lors de la migration vers le protocole HTTPS pour sécuriser les échanges. Une réponse 426 garantit des échanges optimisés.
- Pourquoi ce code est-il envoyé ? Quand le serveur refuse une requête en raison d’un protocole obsolète ou non sécurisé.
- Quels protocoles sont concernés ? Principalement HTTP/2, mais aussi WebSocket ou des versions TLS plus récentes pour la sécurité.
- Comment le résoudre ? Le client doit renvoyer la requête avec les protocoles spécifiés dans l’en-tête Upgrade.
428 Precondition Required
Le code 428 a été créé pour forcer la vérification des conditions avant traitement. Il s’intègre avec le 207 Multi-Status en garantissant la cohérence des opérations multiples. Ce statut résout les erreurs liées à l’absence de validation préalable dans les requêtes complexes.
429 Too Many Requests
Le code 429 signale qu’une limite de taux est atteinte pour une ressource spécifique. Le serveur refuse de traiter la requête tant que le client n’a pas réduit sa fréquence. Utile pour éviter la surcharge, ce statut protège les API en limitant les requêtes abusives ou malveillantes.
- API rate limiting : Bloquer temporairement un client dépassant les requêtes autorisées par seconde.
- DDoS mitigation : Détecter et limiter les attaques par inondation de requêtes simultanées.
- Client-side handling : Forcer le client à respecter des délais avant de réémettre des appels répétés.
431 Request Header Fields Too Large
Le code 431 survient quand les en-têtes HTTP dépassent les limites du serveur. Cela arrive souvent avec des cookies volumineux ou des en-têtes personnalisés. Pour résoudre ce problème, réduisez la taille des données transmises ou ajustez les paramètres serveur comme les buffers de requête.
- Pourquoi ce code est-il renvoyé ? Quand les en-têtes dépassent les capacités du serveur (ex. 8 Ko par défaut dans Apache).
- Quel impact sur les performances ? Une réponse 431 bloque la requête et oblige à modifier les en-têtes ou la configuration serveur.
- Comment les éviter ? Réduire les cookies, utiliser des en-têtes standard, ou augmenter les limites dans les fichiers de configuration.
451 Unavailable For Legal Reasons
Le code 451 signale qu’une ressource est inaccessible en raison d’une obligation légale. Il est utilisé pour signaler des blocages liés à la censure gouvernementale, des ordonnances judiciaires ou des notifications de retrait de contenu. Ce statut inclut un en-tête Link détaillant la loi ou l’entité à l’origine de la restriction.
Les codes d'erreur du serveur (5xx)
Les codes 5xx signalent des erreurs internes côté serveur empêchant le traitement d’une requête. Bien que la syntaxe client soit correcte, ces erreurs nuisent à l’expérience utilisateur et au référencement.
Le code 500 Internal Server Error est le plus courant, suivi par le 503 Service Unavailable en cas de surcharge temporaire.
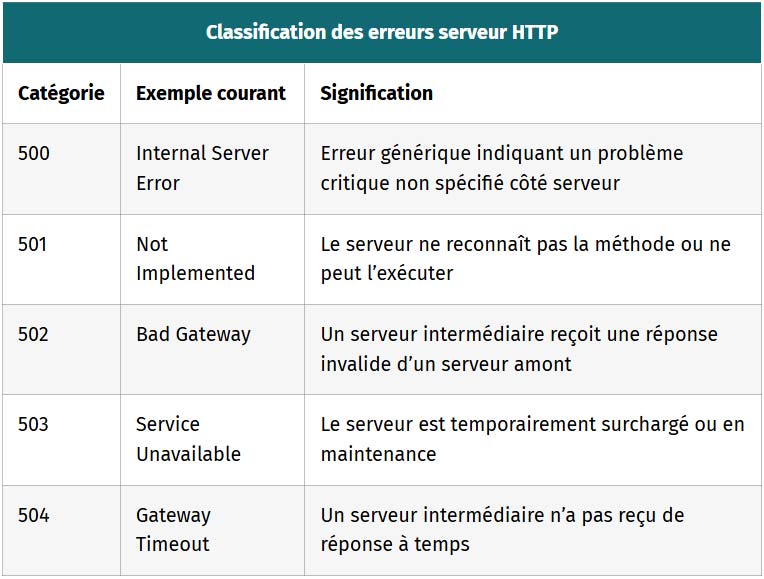
| Classification des erreurs serveur HTTP | ||
|---|---|---|
| Catégorie | Exemple courant | Signification |
| 500 | Internal Server Error | Erreur générique indiquant un problème critique non spécifié côté serveur |
| 501 | Not Implemented | Le serveur ne reconnaît pas la méthode ou ne peut l’exécuter |
| 502 | Bad Gateway | Un serveur intermédiaire reçoit une réponse invalide d’un serveur amont |
| 503 | Service Unavailable | Le serveur est temporairement surchargé ou en maintenance |
| 504 | Gateway Timeout | Un serveur intermédiaire n’a pas reçu de réponse à temps |
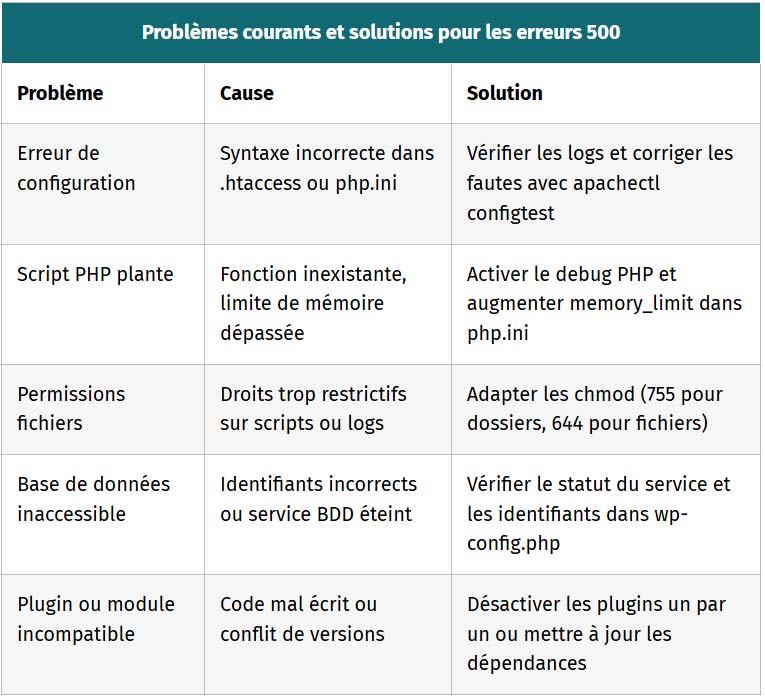
500 Internal Server Error
Le code 500 signale une erreur critique côté serveur, empêchant le traitement d’une requête. Cela peut résulter de fichiers corrompus, d’une base de données inaccessible ou d’un bug applicatif.
Les utilisateurs voient une page blanche ou un message générique, ce qui nuit à l’expérience et au référencement si ces erreurs persistent.
- Quels sont les exemples typiques d’erreurs 500 ? Problèmes de configuration serveur Apache/Nginx, erreurs PHP non capturées, accès refusé aux fichiers critiques, ou crash de base de données.
- Comment diagnostiquer ce code ? Vérifier les logs serveur, tester la config Apache avec apachectl configtest, et valider les connexions BDD ou l’absence de fichiers critiques.
- Quels outils utiliser pour résoudre ce problème ? Les outils de monitoring comme New Relic, les journaux serveur, ou des scripts de vérification automatique des permissions.
| Problèmes courants et solutions pour les erreurs 500 | ||
|---|---|---|
| Problème | Cause | Solution |
| Erreur de configuration | Syntaxe incorrecte dans .htaccess ou php.ini | Vérifier les logs et corriger les fautes avec apachectl configtest |
| Script PHP plante | Fonction inexistante, limite de mémoire dépassée | Activer le debug PHP et augmenter memory_limit dans php.ini |
| Permissions fichiers | Droits trop restrictifs sur scripts ou logs | Adapter les chmod (755 pour dossiers, 644 pour fichiers) |
| Base de données inaccessible | Identifiants incorrects ou service BDD éteint | Vérifier le statut du service et les identifiants dans wp-config.php |
| Plugin ou module incompatible | Code mal écrit ou conflit de versions | Désactiver les plugins un par un ou mettre à jour les dépendances |
501 Not Implemented
Le code 501 Not Implemented survient quand le serveur ne reconnaît pas la méthode HTTP utilisée ou ne peut l’exécuter. Cela arrive avec des méthodes comme PATCH non supportées ou des protocoles incompatibles.
Le client doit modifier sa requête ou adapter le serveur à sa configuration pour prendre en charge la méthode demandée.
- Quand un serveur renvoie-t-il un 501 ? Quand il ne supporte pas la méthode HTTP demandée (ex. PATCH sur un serveur Apache sans module activé).
- Quelles méthodes HTTP ne sont pas supportées ? Méthodes non standard, anciennes versions de HTTP ou fonctionnalités non activées côté serveur.
- Comment résoudre cette erreur côté serveur ? Mettre à jour le serveur, activer les modules requis ou renvoyer un 405 Method Not Allowed si la méthode est refusée.
502 Bad Gateway
Le code 502 Bad Gateway survient quand un serveur intermédiaire reçoit une réponse invalide d’un serveur amont. Cela peut être dû à un backend éteint, des erreurs de configuration ou des problèmes réseau. Ce statut bloque l’accès à la ressource demandée.
- Quelles sont les causes d’un 502 ? Serveur backend éteint, erreurs de configuration proxy, ou problèmes DNS.
- Dans quels cas se produit-il ? Quand un reverse proxy comme Nginx ne peut joindre l’application ou Apache échoue à communiquer avec PHP-FPM.
- Comment le résoudre ? Vérifier le statut du serveur backend, tester les connexions réseau, redémarrer les services ou ajuster la configuration.
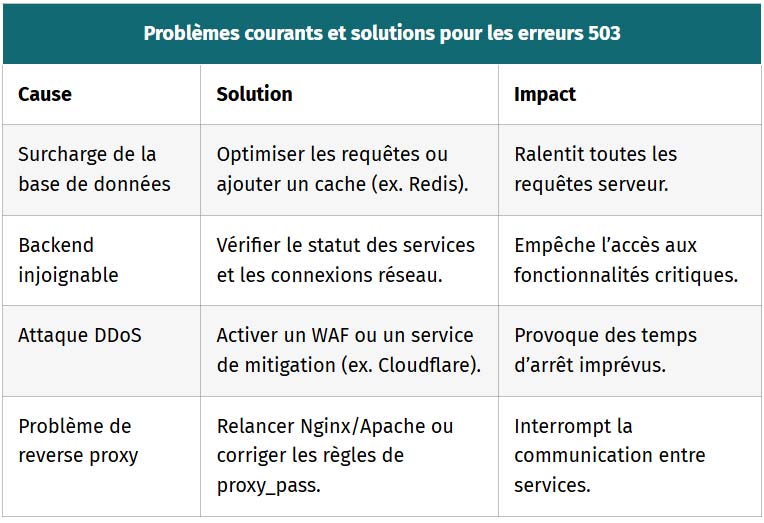
503 Service Unavailable
Le code 503 signale qu’un serveur ne peut traiter une requête à cause de surcharge ou de maintenance. Cela arrive souvent avec des backends lents, des bases de données saturées ou des attaques DDoS.
Les utilisateurs voient une page d’erreur temporaire, ce qui nuit à l’expérience si l’indisponibilité persiste.
- Surcharge serveur : Trop de requêtes simultanées épuisent les ressources (ex. PHP-FPM timeout).
- Maintenance planifiée : Le serveur est en maintenance ou redémarre après une mise à jour.
- Backend défaillant : Un service comme MySQL ou un microservice externe est injoignable.
- Attaque DDoS : Un pic de trafic malveillant paralyse le serveur.
- Problème de configuration : Nginx/Apache mal configuré bloque l’accès aux backends.
| Problèmes courants et solutions pour les erreurs 503 | ||
|---|---|---|
| Cause | Solution | Impact |
| Surcharge de la base de données | Optimiser les requêtes ou ajouter un cache (ex. Redis). | Ralentit toutes les requêtes serveur. |
| Backend injoignable | Vérifier le statut des services et les connexions réseau. | Empêche l’accès aux fonctionnalités critiques. |
| Attaque DDoS | Activer un WAF ou un service de mitigation (ex. Cloudflare). | Provoque des temps d’arrêt imprévus. |
| Problème de reverse proxy | Relancer Nginx/Apache ou corriger les règles de proxy_pass. | Interrompt la communication entre services. |
504 Gateway Timeout
Le code 504 indique qu’un serveur intermédiaire n’a pas reçu de réponse à temps d’un serveur amont. Cela arrive souvent avec des backends lents, des problèmes réseau ou des scripts trop longs.
Les utilisateurs voient une page temporaire, mais une accumulation nuit à l’expérience et au référencement si la latence persiste.
- Temps de réponse dépassé : Un script prend plus de temps que prévu, forçant le proxy à abandonner.
- Problèmes de réseau : Une connexion instable entre le reverse proxy et l’application bloque le traitement.
- Backend non réactif : Une base de données ou un microservice externe ne répond plus, paralysant le serveur.
- Configuration inadaptée
- Comment le résoudre ? Vérifier les logs proxy, tester les temps de réponse, ajuster les timeouts ou redémarrer les services impactés.

505 HTTP Version Not Supported
Le code 505 survient quand le serveur ne supporte pas la version HTTP de la requête. Cela bloque la communication entre client et serveur, nécessitant une mise à jour du protocole ou une adaptation des en-têtes. Bien que rare, cette erreur survient souvent avec des clients anciens ou des proxys mal configurés.
506 Variant Also Negotiates
Le code 506 indique un conflit dans la négociation de contenu. Il survient si aucune variante d’une ressource ne correspond aux en-têtes envoyés (ex. Accept-Language). Le client doit ajuster ses préférences ou configurer les variantes du serveur correctement.
507 Insufficient Storage
Le code 507 Insufficient Storage, défini dans WebDAV, survient quand le serveur manque d’espace pour traiter une requête. Cela bloque les opérations comme les mises à jour de fichiers ou les sauvegardes. Pour résoudre ce problème, libérez de l’espace disque ou ajustez la configuration du serveur.
508 Loop Detected
Le code 508 Loop Detected survient quand un serveur WebDAV détecte un bouclage infini dans les opérations. Cela arrive si des règles de redirection ou des liens symboliques créent un cycle sans fin.
Le serveur bloque le traitement pour éviter une surcharge système. Adapter la configuration ou supprimer les boucles résout le problème.
510 Not Extended
Le code 510 Not Extended, défini par le RFC 2774, signale qu’un serveur ne supporte pas les extensions négociées dans la requête. Cela arrive quand le client spécifie des paramètres inconnus via l’en-tête TE. Le serveur doit indiquer les extensions acceptées pour permettre une nouvelle tentative valide.
511 Network Authentication Required
Le code 511 Network Authentication Required indique que le client doit s’authentifier à travers un proxy avant d’accéder à la ressource. Utilisé par les portails captifs, il inclut un en-tête Location pointant vers une page de connexion.
Contrairement au 307, il impose une authentification réseau avant de suivre la redirection.
- Portail Wi-Fi public : Un hotspot exige une connexion avant d’accéder à internet, redirigeant vers une page de login via l’en-tête Location.
- Proxy d’entreprise : Un réseau professionnel bloque l’accès sans authentification préalable, nécessitant des identifiants valides pour les requêtes sortantes.
- Paiement chez un FAI : Un fournisseur d’accès bloque le trafic tant que l’abonnement n’est pas réglé, forçant une authentification réseau.
Les codes de statut HTTP régissent chaque interaction web, de la réussite (200 OK) à la redirection (301) ou l’erreur (404). Maîtriser ces réponses serveur permet d’optimiser la navigation, améliorer le SEO et résoudre les problèmes avant qu’ils n’impactent les utilisateurs.
Comprendre ces états, c’est anticiper les blocages et sculpter une expérience web fluide, comme un chef affine ses recettes préférées.
Les codes HTTP rythment le web : succès (200), redirection (301), erreur (404).

FAQ
Quels outils pour surveiller les codes HTTP ?
Pour surveiller les codes HTTP, plusieurs outils sont disponibles. Les moniteurs HTTP simulent des requêtes GET/POST pour vérifier la disponibilité et valider les codes de réponse. La surveillance SSL est cruciale pour les sites HTTPS, détectant les erreurs de certificat.
Des outils DNS vérifient les adresses IP et enregistrements DNS, protégeant contre le piratage. Configurez des alertes personnalisables basées sur les temps de chargement, la taille des pages ou l’absence d’éléments cruciaux. Assurez-vous également de la compatibilité IPv4 et IPv6 et testez l’authentification utilisateur si nécessaire.
Comment personnaliser les pages d'erreur 404/500 ?
La personnalisation des pages d’erreur 404 et 500 peut se faire via le fichier `.htaccess` sur un serveur Apache. Créez des pages HTML personnalisées (par exemple, `404.html` et `500.html`) et placez-les dans un répertoire accessible. Modifiez ensuite le fichier `.htaccess` avec les lignes `ErrorDocument 404 /404.html` et `ErrorDocument 500 /500.html` pour rediriger les erreurs vers vos pages personnalisées.
Si votre site est hébergé sur Cloudflare, les plans payants offrent des fonctionnalités d’Error Pages et de Custom Error Rules. Cloudflare permet de définir des pages d’erreur au niveau de la zone ou du compte, avec des règles pour servir un contenu d’erreur personnalisé basé sur des conditions spécifiques. CloudFront est une autre option, permettant de retourner un objet avec un message d’erreur personnalisé en mettant à jour la distribution CloudFront.
Comment les CDN gèrent-ils les codes HTTP ?
Les CDN gèrent les codes HTTP en mettant en cache les réponses réussies (200, 301, 302) et en traitant les erreurs. Lorsqu’une requête arrive, le CDN vérifie si la ressource est en cache. Si oui, il la renvoie avec un code HTTP 200 OK. Sinon, il la récupère depuis le serveur d’origine.
Les CDN peuvent aussi renvoyer des codes d’erreur spécifiques, comme 400 Bad Request pour une requête mal formée, 403 Forbidden pour un problème d’accès, 404 Not Found si le contenu n’existe pas, ou 500 Origin Error si le serveur d’origine ne répond pas. Il est crucial de vérifier si le CDN est activé et que le contenu est cacheable via les en-têtes de réponse HTTP.
Quel est l'impact des codes HTTP sur le mobile ?
Les codes HTTP ont un impact significatif sur l’expérience mobile, influençant la performance, le SEO et la satisfaction utilisateur. Les codes 200 (OK) assurent l’accessibilité des ressources, tandis que les codes 301/302 peuvent ralentir le chargement. Les codes 404 nuisent à l’expérience, et les codes 500 affectent la disponibilité du site.
Pour optimiser l’expérience mobile, minimisez la taille des fichiers, utilisez la mise en cache et un CDN, priorisez le contenu visible et évitez les redirections inutiles. Un site mobile performant améliore l’engagement, les conversions et le positionnement dans les résultats de recherche, et l’adoption de technologies comme les PWA et AMP est recommandée.
Comment optimiser les codes HTTP pour l'API ?
Pour optimiser les codes HTTP pour une API, utilisez-les de manière cohérente et précise pour refléter le résultat des requêtes. Les codes 2xx indiquent le succès, comme 200 OK ou 201 Created pour une nouvelle ressource. Les codes 4xx signalent des erreurs client, comme 400 Bad Request ou 404 Not Found. Les codes 5xx indiquent des erreurs serveur, comme 500 Internal Server Error.
Utilisez le code le plus spécifique possible pour chaque situation. Fournissez des informations claires dans le corps de la réponse pour aider le client à comprendre et corriger le problème. Incluez des en-têtes appropriés, comme « Location » après une création réussie (201 Created), pour indiquer l’URI de la nouvelle ressource.
Comment débuguer les erreurs HTTP courantes ?
Pour déboguer les erreurs HTTP courantes, comprenez les codes de réponse : 1xx (informations), 2xx (succès), 3xx (redirections), 4xx (erreurs client) et 5xx (erreurs serveur). Pour les erreurs client (4xx), vérifiez l’URL et la méthode HTTP. Pour les erreurs 401/403, examinez l’authentification et les droits d’accès.
Pour les erreurs serveur (5xx), le problème est côté serveur. Les erreurs courantes incluent 500, 502, 503 et 504, dues à des problèmes de code, une surcharge ou une panne matérielle. Utilisez des outils comme Google Search Console ou `ngrok` pour tester les pages et diagnostiquer les problèmes, en gardant à l’esprit que les corrections peuvent prendre quelques jours à être reflétées.







