
Travailler avec des données non structurées peut rapidement devenir un casse-tête quand on cherche à développer des modèles prédictifs efficaces.
L’apprentissage supervisé offre une solution puissante à ce problème en utilisant des données étiquetées pour entraîner des algorithmes capables de reconnaître des patterns et de faire des prédictions précises.
Dans cet article, nous explorerons les fondements de cette technique de machine learning, ses différentes applications et les étapes clés pour implémenter vos propres modèles prédictifs.
Vidéo : Introduction claire au machine learning supervisé
Dans cette vidéo, Alexandre TL nous explique ce qu’est l’apprentissage supervisé. Il nous explique aussi les différences entre apprentissage supervisé, non supervisé et par renforcement, tout en illustrant les concepts de régression, classification et l’importance des réseaux de neurones.
Sommaire
Qu'est-ce que l'apprentissage supervisé ?
Définition et principes fondamentaux
L’apprentissage supervisé constitue une branche importante du machine learning et de l’intelligence artificielle. Cette méthode utilise des ensembles de données étiquetées, souvent issues du Big Data ou mégadonnées, pour entraîner des algorithmes capables de classer des informations ou de prédire des résultats avec précision.
Étant donné que l’algorithme reçoit à la fois les données d’entrée et les sorties attendues, il peut progressivement affiner ses prédictions en comparant ses résultats aux valeurs correctes.
Le processus d’apprentissage supervisé repose entièrement sur l’utilisation de données préalablement étiquetées. Ce système fonctionne comme un professeur qui guide l’algorithme en lui montrant des exemples corrects pour qu’il puisse apprendre à reconnaître des patterns et à établir des relations.
L’objectif final est de créer un modèle capable de généraliser ses connaissances pour traiter correctement de nouvelles données jamais rencontrées auparavant.
L’apprentissage supervisé est un pilier du machine learning et de l’IA.

Fonctionnement d'un algorithme d'apprentissage supervisé
Le fonctionnement d’un algorithme d’apprentissage supervisé suit plusieurs étapes clés qui permettent de passer des données brutes à un modèle prédictif performant.
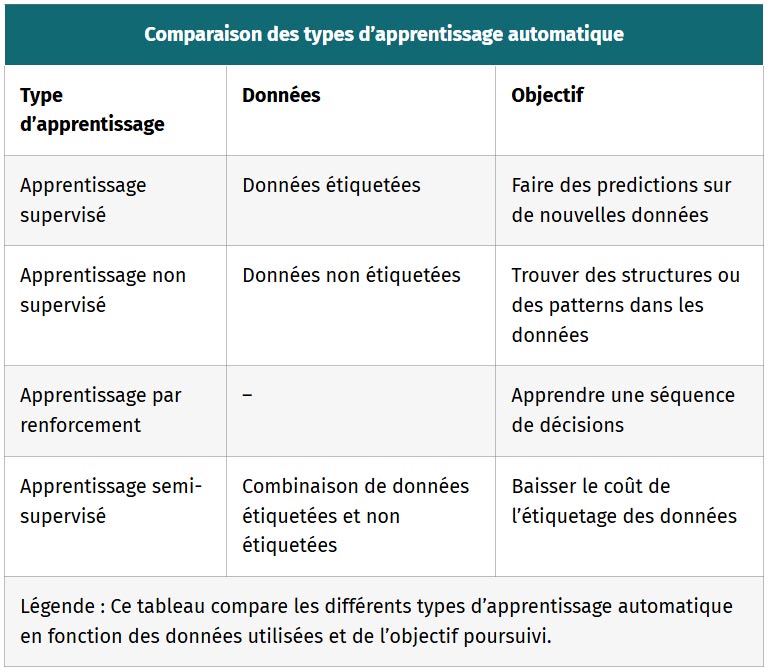
| Comparaison des types d’apprentissage automatique | ||
|---|---|---|
| Type d’apprentissage | Données | Objectif |
| Apprentissage supervisé | Données étiquetées | Faire des predictions sur de nouvelles données |
| Apprentissage non supervisé | Données non étiquetées | Trouver des structures ou des patterns dans les données |
| Apprentissage par renforcement | – | Apprendre une séquence de décisions |
| Apprentissage semi-supervisé | Combinaison de données étiquetées et non étiquetées | Baisser le coût de l’étiquetage des données |
| Légende : Ce tableau compare les différents types d’apprentissage automatique en fonction des données utilisées et de l’objectif poursuivi. | ||
L’entraînement d’un modèle d’apprentissage supervisé commence par la division des données en ensembles d’apprentissage et de test. Pendant la phase d’entraînement, le modèle analyse les données étiquetées et ajuste ses paramètres pour minimiser l’écart entre ses prédictions et les valeurs réelles.
La validation croisée permet ensuite d’évaluer la performance du modèle en le testant sur différentes portions des données. Cette méthodologie garantit que le modèle pourra généraliser efficacement ses apprentissages face à de nouvelles informations.

Types de problèmes résolus par l'apprentissage supervisé
Classification
La classification en apprentissage supervisé consiste à attribuer une étiquette ou une catégorie à des données d’entrée.
Dans le monde des projets tech, la classification trouve des applications intéressantes. Par exemple, les filtres anti-spam utilisent des algorithmes de classification pour déterminer si un email est légitime ou indésirable.
Pour les développeurs travaillant sur la reconnaissance d’images, ces techniques permettent d’identifier automatiquement des objets dans une photo, comme distinguer un chat d’un chien.
Les systèmes de détection de fraude dans le secteur bancaire s’appuient également sur ces méthodes pour repérer les transactions suspectes en temps réel.

Régression
La régression diffère de la classification, car elle prédit des valeurs numériques continues plutôt que des catégories. Contrairement à la classification qui attribue une étiquette à une donnée, la régression estime une valeur précise comme un prix ou une température.
Ces modèles cherchent à comprendre les relations entre variables pour faire des prédictions précises.
- Régression linéaire : Idéale pour modéliser des relations linéaires entre les variables.
- Régression polynomiale : Utile pour capturer des relations non linéaires avec des courbes.
- Régression ridge : Permet de réduire la complexité du modèle et éviter le surapprentissage.
- Régression lasso : Effectue une sélection de variables en pénalisant les coefficients.
Les applications de la régression sont nombreuses et touchent à des domaines variés. Dans l’immobilier, les algorithmes prédisent les prix des logements en fonction de caractéristiques comme la surface, l’emplacement ou le nombre de pièces. Les analystes financiers utilisent la régression pour estimer le rendement d’un portefeuille d’actions.
Dans le domaine de la logistique, ces techniques aident à prévoir les volumes de commandes pour optimiser les stocks et la chaîne d’approvisionnement. Grâce à ces prédictions, les entreprises peuvent anticiper la demande et prendre des décisions stratégiques basées sur des données concrètes.

Algorithmes d'apprentissage supervisé
Algorithmes de classification
Les algorithmes de classification représentent une famille importante dans le monde de l’apprentissage supervisé. La régression logistique, les forêts aléatoires, les machines à vecteurs de support (SVM) et les réseaux neuronaux constituent les principaux outils de cette catégorie.
Chacun possède des forces distinctes : la régression logistique excelle dans sa simplicité pour les classifications binaires, tandis que les forêts aléatoires combinent plusieurs arbres de décision pour une robustesse accrue face aux données complexes.
Le choix d’un algorithme de classification dépend largement du problème que vous cherchez à résoudre. La taille et la nature de vos données, ainsi que vos contraintes en termes de ressources informatiques, orientent cette décision importante.
Les algorithmes simples comme la régression logistique offrent une rapidité d’exécution appréciable, mais peuvent manquer de précision pour des données aux relations non linéaires.
À l’inverse, des techniques plus sophistiquées comme les réseaux neuronaux permettent d’atteindre une précision remarquable, mais exigent davantage de puissance de calcul et de temps d’entraînement.
L’avenir pourrait voir ces limitations résolues grâce aux avancées de l’informatique quantique qui promet de révolutionner les capacités de calcul pour l’intelligence artificielle.
Les algorithmes de classification sont au cœur de l’apprentissage supervisé.

Algorithmes de régression
Les algorithmes de régression constituent l’autre pilier fondamental de l’apprentissage supervisé et permettent de prédire des valeurs continues plutôt que des catégories.
- Régression linéaire : Idéale pour modéliser des relations linéaires entre les variables.
- Régression polynomiale : Utile pour capturer des relations non linéaires avec des courbes.
- Régression ridge : Permet de réduire la complexité du modèle et éviter le surapprentissage.
- Régression lasso : Effectue une sélection de variables en pénalisant les coefficients.
Chaque type d’algorithme de régression répond à des besoins spécifiques selon le contexte d’utilisation.
La régression linéaire reste le choix privilégié pour des relations simples entre variables, grâce à sa rapidité d’exécution et sa facilité d’interprétation.
Pour des relations plus complexes avec des courbures, la régression polynomiale offre davantage de flexibilité en capturant les tendances non linéaires.
Les méthodes ridge et lasso interviennent particulièrement dans les situations où le nombre de variables explicatives est important et qu’une régularisation devient nécessaire pour éviter le surapprentissage.

Applications pratiques de l'apprentissage supervisé
Applications dans le domaine du marketing et du commerce
L’apprentissage supervisé transforme radicalement les stratégies marketing en permettant une segmentation client plus fine et personnalisée. Les modèles prédictifs analysent les comportements d’achat antérieurs pour identifier des groupes ayant des préférences similaires.
Les entreprises utilisent désormais ces techniques pour anticiper la demande et détecter les fraudes avec une efficacité remarquable. Un algorithme entraîné sur des données historiques de ventes peut prévoir les tendances futures en tenant compte des saisonnalités et des événements spéciaux.
La détection de fraude bénéficie également de l’apprentissage supervisé en analysant des milliers de transactions pour repérer des comportements suspects.
Ces applications offrent un avantage concurrentiel majeur en permettant aux entreprises de réagir proactivement plutôt que rétroactivement face aux évolutions du marché.

Applications dans le traitement d'images et le traitement du langage naturel
Dans le domaine du traitement d’images, les algorithmes d’apprentissage supervisé excellent à reconnaître et catégoriser automatiquement les éléments visuels après avoir été entraînés sur des milliers d’exemples étiquetés.
Le traitement du langage naturel représente un autre terrain d’application particulièrement fertile pour ces techniques. Les modèles d’analyse de sentiments évaluent les opinions exprimées dans les commentaires clients ou sur les réseaux sociaux, offrant aux entreprises un aperçu précieux de leur réputation.
La traduction automatique a connu des progrès spectaculaires grâce aux réseaux de neurones entraînés sur des millions de paires de phrases traduites. Les transformers comme BERT et GPT ont révolutionné la compréhension contextuelle du langage en captant des nuances sémantiques auparavant inaccessibles aux machines.
Cette sophistication croissante rend d’ailleurs essentiel de savoir comment identifier le contenu généré par IA dans notre quotidien numérique.

Applications médicales et scientifiques
Le secteur médical bénéficie considérablement des avancées en apprentissage supervisé, notamment pour l’aide au diagnostic et l’interprétation d’images médicales. Les algorithmes entraînés peuvent détecter des anomalies sur des radiographies ou des IRM avec une précision parfois supérieure à celle des médecins.
Dans le domaine scientifique, ces méthodes accélèrent la recherche et la découverte de connaissances. Les modèles prédictifs aident à anticiper l’évolution de maladies en fonction de biomarqueurs spécifiques.
La prédiction de structures protéiques, longtemps considérée comme un défi majeur, a fait des progrès remarquables grâce à des algorithmes comme AlphaFold.
Ces applications souffrent néanmoins de certaines limitations, notamment le besoin de données médicales de qualité et les questions éthiques liées à leur utilisation.
L’apprentissage supervisé révolutionne le diagnostic médical et l’analyse d’images.
Applications industrielles
L’apprentissage supervisé offre de nombreuses applications dans le secteur industriel.
- Maintenance prédictive : Anticiper les pannes et optimiser les interventions.
- Contrôle qualité : Identifier automatiquement les défauts de production.
- Optimisation des processus : Ajuster les paramètres pour maximiser l’efficacité.
- Automatisation industrielle : Contrôler les robots et les machines pour améliorer la production.
L’intégration de ces technologies dans les environnements de production permet des gains d’efficacité considérables.
Les usines intelligentes utilisent l’apprentissage supervisé pour optimiser la consommation énergétique tout en maintenant des niveaux de production optimaux.
Les entreprises manufacturières voient leurs coûts opérationnels diminuer grâce à la réduction des arrêts non planifiés et l’amélioration de la qualité des produits.
Malgré ces avantages, l’implémentation de ces solutions en milieu industriel présente des défis spécifiques. La résistance au changement et le manque de compétences techniques constituent souvent les principaux obstacles à surmonter.
L’apprentissage supervisé transforme notre capacité à extraire du sens des données étiquetées, que ce soit pour classifier des informations ou prédire des valeurs par régression. Cette approche, pilier fondamental du machine learning moderne, trouve des applications concrètes dans pratiquement tous les secteurs d’activité.
En maîtrisant ses principes, vous disposerez d’un outil puissant pour résoudre des problèmes complexes et prendre des décisions basées sur les données.

FAQ
Quels sont les défis de l'apprentissage supervisé ?
L’apprentissage supervisé, malgré sa puissance, confronte les développeurs à des défis notables. L’overfitting, ou surapprentissage, est un risque majeur où le modèle excelle sur les données d’entraînement mais échoue à généraliser sur de nouvelles données. Pour contrer cela, l’utilisation d’un ensemble de validation est cruciale pour évaluer indépendamment les progrès de l’algorithme.
La qualité des données étiquetées est également primordiale. Des données incorrectes ou incomplètes compromettent l’apprentissage du modèle. De plus, la complexité du modèle doit être maîtrisée pour éviter des difficultés d’interprétation et de débogage. Enfin, la collecte et l’étiquetage des données peuvent s’avérer coûteux en temps et en ressources.
Comment choisir le bon algorithme supervisé ?
Le choix de l’algorithme d’apprentissage supervisé idéal dépend de plusieurs facteurs clés. Le type de données, les objectifs de l’organisation et la complexité du problème sont autant d’éléments à considérer. Il n’existe pas de solution universelle, mais plutôt une approche adaptée à chaque situation.
Parmi les algorithmes courants, on retrouve la régression linéaire, les machines à vecteurs de support (SVM), les arbres de décision et les réseaux neuronaux. Chaque algorithme possède ses propres forces et faiblesses, et le choix dépendra des spécificités du projet et des ressources disponibles. Un travail préparatoire important, notamment l’étiquetage des données et l’ajustement de la précision, est essentiel pour optimiser les performances du modèle.
Quelles sont les limites de l'apprentissage supervisé ?
Bien que puissant, l’apprentissage supervisé présente des limitations importantes. La dépendance aux données étiquetées est un frein, car l’étiquetage manuel est coûteux et chronophage. De plus, si les données d’entraînement sont biaisées, le modèle reproduira ces biais, menant à des résultats inéquitables.
Le besoin de grandes quantités de données est également un défi, augmentant les besoins en ressources matérielles et le temps d’apprentissage. La généralisation du modèle peut être limitée si les nouvelles données diffèrent trop de celles utilisées pour l’entraînement. Enfin, la complexité de conception et de mise en œuvre nécessite une expertise en machine learning.
Comment évaluer la performance d'un modèle supervisé ?
L’évaluation de la performance d’un modèle supervisé est essentielle pour garantir son efficacité et sa capacité à généraliser. Différentes mesures d’évaluation existent, et le choix de la mesure appropriée influence l’interprétation des résultats. Pour les modèles de classification, la matrice de confusion est un outil précieux, résumant les prédictions correctes et incorrectes.
À partir de la matrice de confusion, des métriques telles que l’accuracy, la précision, le rappel et le score F1 peuvent être calculées. Pour les modèles de régression, l’erreur quadratique moyenne (MSE) et l’erreur absolue moyenne (MAE) sont couramment utilisées. Comprendre le contexte du problème et les objectifs du modèle est crucial pour sélectionner la métrique la plus pertinente et déployer un modèle performant.
Comment l'apprentissage semi-supervisé diffère-t-il ?
L’apprentissage semi-supervisé est une approche hybride combinant l’apprentissage supervisé et non supervisé. La principale différence réside dans les données utilisées pour l’entraînement : l’apprentissage supervisé utilise des données entièrement étiquetées, tandis que l’apprentissage semi-supervisé utilise une combinaison de données étiquetées et non étiquetées.
Cette approche est particulièrement utile lorsque l’obtention de données étiquetées est coûteuse ou difficile, tandis que les données non étiquetées sont plus facilement accessibles. Les techniques d’apprentissage semi-supervisé modifient ou complètent un algorithme supervisé de base pour intégrer des informations provenant d’exemples non étiquetés, permettant de tirer le meilleur parti des données disponibles tout en réduisant les efforts d’étiquetage manuel.
Quels sont les outils pour l'apprentissage supervisé ?
L’apprentissage supervisé s’appuie sur des outils et des frameworks pour faciliter la création de modèles. Les frameworks, tels que TensorFlow développé par Google, fournissent des environnements de travail avec des bibliothèques et des outils pour simplifier le développement de modèles de machine learning. Ils permettent d’éviter la duplication de code et de produire de meilleurs modèles de conception.
En résumé, les outils pour l’apprentissage supervisé incluent des algorithmes de classification et de régression, ainsi que des frameworks comme TensorFlow. Ces outils permettent aux entreprises d’automatiser des tâches, de prédire des événements futurs et d’améliorer la prise de décision, en tirant parti de la puissance des données étiquetées.






