
Le web moderne est partout, mais saviez-vous qu’il a débuté comme une simple vitrine statique ? Le web 1.0, cette ère oubliée de 1990 à 2004, a posé les bases de tout ce que vous utilisez aujourd’hui.
À l’époque, les sites ressemblaient à des brochures numériques, avec du texte, peu d’images et aucune interactivité. Conçu par Tim Berners-Lee au CERN pour partager des données scientifiques, il reposait sur l’HTML, l’HTTP et les URL, toujours présents dans le web actuel.
En comprenant son fonctionnement, vous verrez pourquoi les réseaux sociaux, les vidéos en ligne ou les moteurs de recherche n’auraient pas été possibles sans cette première révolution silencieuse.
Sommaire
Retour vers le futur : qu'est-ce que le web 1.0 ?
Le Web 1.0, né en 1990 et actif jusqu’en 2004, est le web statique. Imaginez un Internet sans réseaux sociaux, sans commentaires, sans interactivité. Les sites ressemblaient à des brochures en ligne, avec un contenu fixe.
Les origines du web, un projet pour scientifiques
Inventé par Tim Berners-Lee au CERN en 1989, le web visait à faciliter le partage d’informations entre chercheurs. Le premier site, info.cern.ch (1991), explique le projet WWW via des liens hypertexte.
L'internet "lecture seule", une définition simple
Le Web 1.0 est unidirectionnel : les utilisateurs lisaient sans interagir. Les pages, statiques et minimalistes (texte/images), nécessitaient des mises à jour manuelles. Un peu comme un livre en ligne sans possibilité d’annotation.
Une ère bien définie, de 1990 à 2004
De 1990 à 2004, le web se développe lentement. En 1993, le CERN le rend libre. Le navigateur Mosaic (1993) le démocratise, malgré des connexions 56K limitantes. Cette période pave la route au Web 2.0, plus interactif.

À quoi ressemblait vraiment le web à ses débuts ?
En 1995, le web 1.0 ressemblait à un livre statique : textes, liens bleus, et GIF clignotants. Aucun commentaire, aucun partage. Les utilisateurs étaient des spectateurs, pas des acteurs.
Naviguer à l'aveugle, l'ère des annuaires en ligne
Pas de Google. La recherche passait par Yahoo! Directory (1994), qui classait manuellement les sites en catégories. Pour trouver des voitures, il fallait parcourir « Transports > Automobile ». Une mauvaise étiquette, et c’était la galère. AltaVista (1995) automatisait l’indexation, mais seul le mot-clé exact fonctionnait. Une erreur, et la page restait vide.
Un design dicté par la technique
Les sites s’affichaient sur des écrans 800×600 pixels. Les créateurs alignaient tout en HTML avec des tableaux, des cadres, des fonds mosaïques basiques. Les GIF animés, péniblement fluides, tournaient en boucle.
Un modem 56k transformait chaque clic en attente : une image de 100 Ko prenait 15 secondes. La moindre lourdeur, et les internautes rageaient.
L'expérience d’un spectateur passif
Sur le web 1.0, vous étiez un lecteur dans une bibliothèque numérique. Vous pouviez lire les pages, mais pas y écrire.
Les pages restaient fixes. Un formulaire de contact était une rareté. Pas de likes, de partages, de profils. La seule interaction ? Un e-mail envoyé manuellement. Le web était un monologue. Chaque visiteur voyait le même contenu, sans personnalisation. L’ère du spectateur absolu.

Les technologies qui ont bâti le premier web
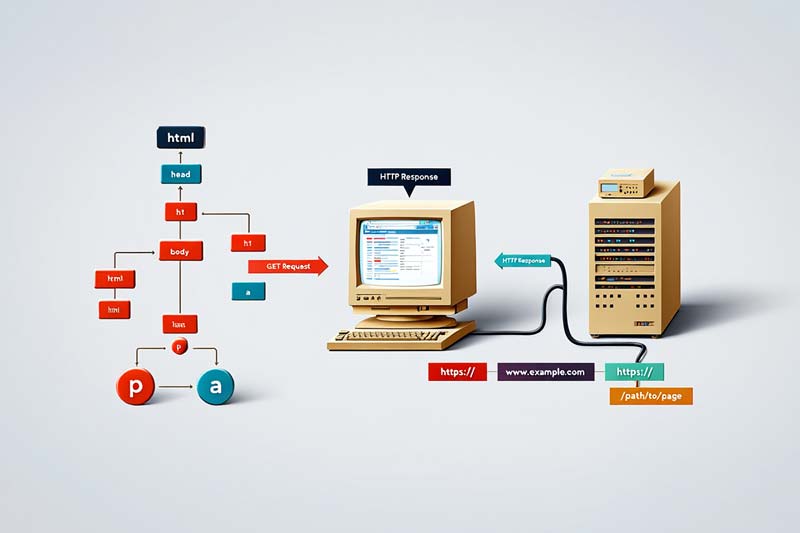
Le trio fondateur : HTML, HTTP et URL
Le Web 1.0 repose sur trois piliers fondamentaux.
Le HTML structure les pages, comme un plan détaillé organisant titres et liens.
L’HTTP permet le dialogue entre navigateur et serveur : en tapant une adresse, ce protocole récupère la page.
Enfin, les URL attribuent une adresse unique à chaque ressource. Ces trois éléments ont rendu le web fonctionnel dès ses débuts.
Les serveurs et navigateurs de la première heure
Les premiers sites utilisaient des technologies basiques. Les serveurs Apache et Microsoft IIS diffusaient des pages HTML statiques. Netscape Navigator puis Internet Explorer imposaient leur lecture, avec des rendus variables. Cette diversité obligeait les développeurs à des ajustements constants. Leur héritage persiste dans l’infrastructure actuelle.
- HTML : Structurer le contenu
- HTTP : Échanger entre navigateur et serveur
- URL : Localiser chaque ressource
- CSS (limité) : Premières stylisations basiques
- Serveurs web : Apache et IIS pour distribuer les fichiers
Du statique au dynamique, la grande comparaison
Web 1.0 vs web 2.0 : l'arrivée de l'interaction
Le Web 1.0 (1990-2004) ressemblait à une encyclopédie en ligne. Sites comme Britannica Online offraient un contenu fixe, sans interaction. HTML et HTTP limitaient l’expérience à des formulaires basiques. Vous lisiez, mais ne contribuiez pas.
Le Web 2.0, lancé en 2004, vous transforme en créateur. Éditez Wikipédia, commentez YouTube, partagez sur Facebook : des APIs sociales (Twitter, Instagram) rendent le web collaboratif. Des partages sur Instagram aux avis Amazon, le Web 2.0 incarne l’ère participative.
Le Web 2.0, lancé en 2004, vous transforme en créateur.
Un aperçu du web 3.0 et au-delà
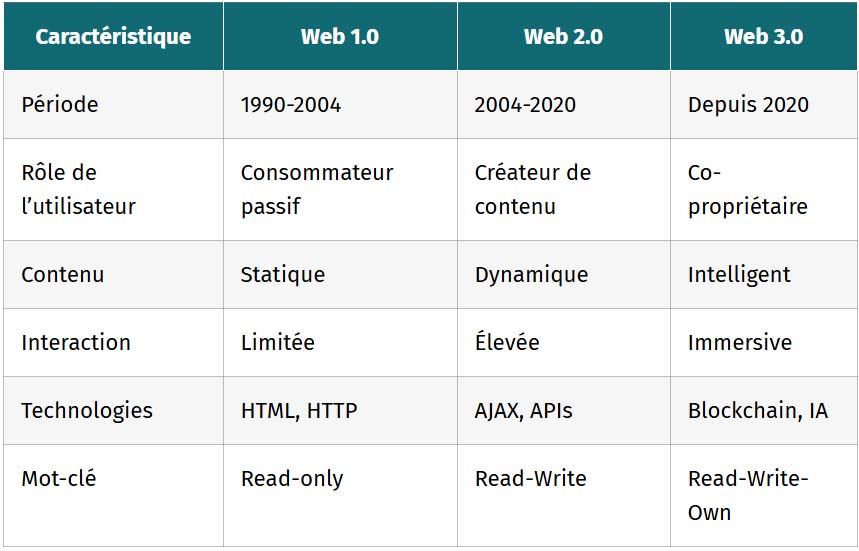
| Caractéristique | Web 1.0 | Web 2.0 | Web 3.0 |
|---|---|---|---|
| Période | 1990-2004 | 2004-2020 | Depuis 2020 |
| Rôle de l’utilisateur | Consommateur passif | Créateur de contenu | Co-propriétaire |
| Contenu | Statique | Dynamique | Intelligent |
| Interaction | Limitée | Élevée | Immersive |
| Technologies | HTML, HTTP | AJAX, APIs | Blockchain, IA |
| Mot-clé | Read-only | Read-Write | Read-Write-Own |
Le Web 3.0 (depuis 2020) repose sur la décentralisation. Vos données quittent les serveurs de Google/Meta pour la blockchain.
Les NFT offrent des ventes directes sans intermédiaire. L’IA personnalise les résultats en comprenant le contexte des requêtes. Un réseau social où vous contrôlez données et revenus : voilà l’idéal du Web 3.0.

Les premiers pas du business en ligne
Quand le marketing s'invitait sur la toile
Le marketing digital du Web 1.0 s’inspirait des méthodes traditionnelles.La première bannière en 1994 sur Hotwired, commandée par AT&T, affichait « Avez-vous déjà cliqué votre souris juste ICI => VOUS LE FEREZ » avec un taux de clics record de 44%.
Les premières publicités en ligne étaient une révolution. Pour la première fois, on pouvait mesurer un retour sur investissement, même s’il ne s’agissait que de compter les clics.
Les pop-ups, inventées en 1997 par Ethan Zuckerman, devenaient emblématiques du Web 1.0 malgré leur réputation intrusive.
E-commerce et visibilité, les stratégies de l'époque
Amazon (1995) marquait le début du commerce en ligne avec des catalogues statiques. Le référencement reposait sur :
- Inscription dans les annuaires web : La principale source de trafic
- Utilisation de balises meta-keywords : Renseigner une liste de mots-clés dans le code
- Bourrage de mots-clés : Répéter massivement un terme pour tromper les moteurs de recherche
- Bannières publicitaires : Le premier format d’affichage
Le Web 1.0 posait les bases du business en ligne avec des outils novateurs, préfigurant l’évolution vers une expérience interactive.
Amazon marquait le début du commerce en ligne.

L'héritage du web 1.0, les fondations de notre internet
Le Web 1.0 (1991-2004) proposait des sites statiques nécessitant des mises à jour manuelles. Les utilisateurs se limitaient à la consultation, sans interactivité possible. Cette structure rigide posait les bases d’un internet encore balbutiant.
Les limites qui ont poussé à l'évolution
L’absence de dynamisme et les connexions 56K ralentissaient l’expérience.
Seuls les webmasters géraient les mises à jour, rendant le Web 2.0 inévitable. Les utilisateurs ne pouvaient pas créer de contenu ni interagir avec les sites.
Ce que nous devons au web statique
Malgré ses limites, le Web 1.0 a permis
- la démocratisation de l’information
- l’établissement d’HTTP, d’URL et du HTML
- la naissance des hyperliens
Tim Berners-Lee a lancé le premier site en 1991, posant les bases d’internet moderne. Ces protocoles restent utilisés aujourd’hui, même si leur usage s’est transformé avec les générations suivantes du web.
Le Web 1.0, malgré son côté statique, a démocratisé l’information et posé les bases techniques d’internet. Ses limites – manque d’interactivité, mise à jour manuelle – ont stimulé l’évolution vers un web social. Sans cette première étape, notre expérience numérique actuelle, riche et collaborative, n’aurait jamais vu le jour. Une fondation indispensable, souvent oubliée, mais essentielle à l’histoire du web.

FAQ : Web 1.0 : L’Ère de l’Internet Statique et des Sites Vitrine
Qu’est-ce que le web 1.0 et pourquoi est-il surnommé "internet statique" ?
Le web 1.0, actif entre 1990 et 2004, est la première version d’internet que vous pouvez imaginer comme une bibliothèque numérique unidirectionnelle. Les sites étaient statiques, avec des pages HTML basiques, peu de design et zéro interactivité. Le contenu était conçu par des webmasters et les utilisateurs ne pouvaient que lire, sans commenter ou interagir. Son surnom « statique » vient du fait que les pages ne changeaient quasiment jamais, sauf mise à jour manuelle. En clair, c’était l’ère de la diffusion d’information, pas de la participation.
Quelle est la différence entre le web 1.0 et le web 2.0, surtout en contexte de grand oral ?
La différence clé tient en un mot : interactivité. Le web 1.0 était « lecture seule », avec des sites en lecture fixe, des formulaires basiques et des annuaires comme Yahoo! Directory. Le web 2.0, apparu vers 2004, a tout changé avec les réseaux sociaux, les blogs et Wikipédia. Vous pouvez maintenant créer du contenu, commenter, liker. Pour un grand oral, retenez que le web 2.0 est collaboratif alors que le web 1.0 était une autoroute de l’information sans retour. Le passage du statique au dynamique a révolutionné l’usage, passant de spectateur à acteur.
Pourquoi qualifie-t-on le web 1.0 de "web passif" ?
Parce que les utilisateurs n’avaient qu’un rôle d’observateur, sans possibilité d’engagement. Sur une page web 1.0, vous lisiez du texte, cliquiez sur des liens hypertextes, peut-être remplissiez un formulaire de contact, mais c’était tout. Aucun commentaire, aucun partage, zéro profil utilisateur. Autrement dit, c’était une télévision numérique : vous regardiez, mais vous ne participiez pas. Cette passivité s’explique par les technologies de l’époque, limitées à l’HTML et aux serveurs Apache, sans bases de données dynamiques ou scripts interactifs.
Quels sont les trois niveaux du web et leurs rôles respectifs ?
Les trois niveaux du web sont souvent confondus avec les versions (1.0, 2.0, 3.0), mais ils décrivent plutôt sa structure technique. Le web de surface est ce que les moteurs de recherche indexent (sites publics). Le web profond regroupe les contenus non indexés (intranets, pages protégées). Le web clandestin, ou « dark web », nécessite des navigateurs spéciaux pour accéder à des réseaux anonymisés. En clair, ces niveaux ne correspondent pas aux générations du web, mais à la visibilité et l’accessibilité des données. Le web 1.0 n’existait que sur le surface, avec peu de profondeur technique.
Quel est le site web le plus visité de l’ère 1.0 ?
À l’époque du web 1.0, les stars étaient des annuaires comme Yahoo! Directory ou des sites institutionnels comme Britannica Online. Mais le concept de « site n°1 » n’était pas aussi clair qu’aujourd’hui. En 2023, Google, YouTube et Facebook dominent, grâce au web 2.0. Le web 1.0, lui, n’aurait jamais pu héberger ces géants, faute d’interactivité ou de mise en ligne collaborative. Autrement dit, le « n°1 » d’hier était un site d’entreprise ou une encyclopédie en ligne, pas une plateforme sociale.
Quelles sont les trois bases techniques fondamentales du web, héritées du web 1.0 ?
Les trois piliers techniques du web, toujours en usage, sont l’HTML (structure des pages), l’HTTP (protocole d’échange entre votre appareil et le serveur), et les URL (adresses uniques pour chaque page). Même si le web a évolué, ces technologies sont ses fondations. Par exemple, une page web d’aujourd’hui utilise toujours l’HTML, bien que versionnée, et les URL restent la carte d’identité numérique d’un site. Sans ces bases, pas de web 2.0 ou 3.0. C’est un peu comme les fondations d’une maison : invisibles mais indispensables.
Que signifient les termes web 1.0, 2.0 et 3.0 dans l’évolution du web ?
Ces chiffres décrivent l’histoire du web en trois étapes. Le web 1.0 (1990-2004) est la base : pages statiques, lecture seule, partage d’info. Le web 2.0 (2004-2020) ajoute l’interactivité : réseaux sociaux, commentaires, contenu généré par les utilisateurs. Le web 3.0 (depuis 2020) mise sur l’intelligence artificielle, la blockchain et la décentralisation pour un web personnalisé et sécurisé. En résumé, de « lire » à « lire-écrire » puis à « lire-écrire-posséder ». Ce n’est pas une révolution technique, mais un changement de paradigme utilisateur.
Pourquoi la transition du web 1.0 au 2.0 a-t-elle permis à n’importe qui de devenir créateur de contenu ?
Le web 1.0 réservait la création aux webmasters, avec des compétences en HTML et un accès serveur. Le web 2.0 a démocratisé les outils : blogs, réseaux sociaux, outils visuels ont rendu la publication accessible à tous. Par exemple, un internaute lambda pouvait lancer un blog avec Blogger ou poster sur MySpace sans coder. Cette évolution s’appuyait sur des technologies comme l’AJAX et les API, permettant des interactions en temps réel. Ainsi, le web 2.0 a transformé les utilisateurs en producteurs, ouvrant la voie aux influenceurs et contenus UGC (générés par les utilisateurs).
Quels sont les trois services web les plus populaires aujourd’hui et comment diffèrent-ils du web 1.0 ?
Les services les plus utilisés en 2023 sont les moteurs de recherche (Google), les réseaux sociaux (Facebook, TikTok), et les services de streaming (YouTube, Netflix). Ces outils web 2.0 reposent sur l’interaction, le contenu dynamique et l’IA. À l’inverse, les services web 1.0 se limitaient aux annuaires (Yahoo!), aux e-mails (Hotmail) et à des plateformes de partage de fichiers comme Napster. En clair, le web d’hier était une vitrine, celui d’aujourd’hui est une scène ouverte où tout le monde peut jouer un rôle.







